Introduction
Task Description
Software
Data
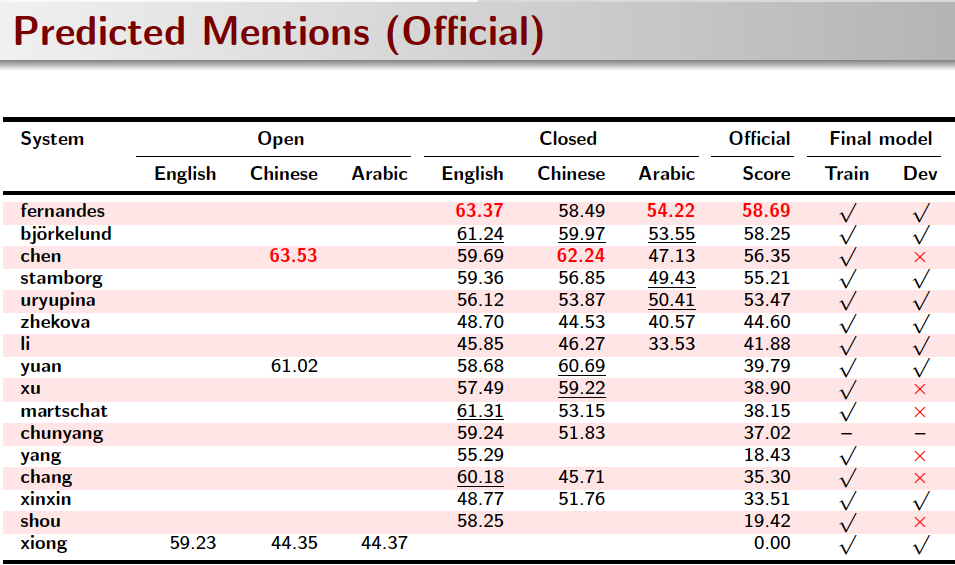
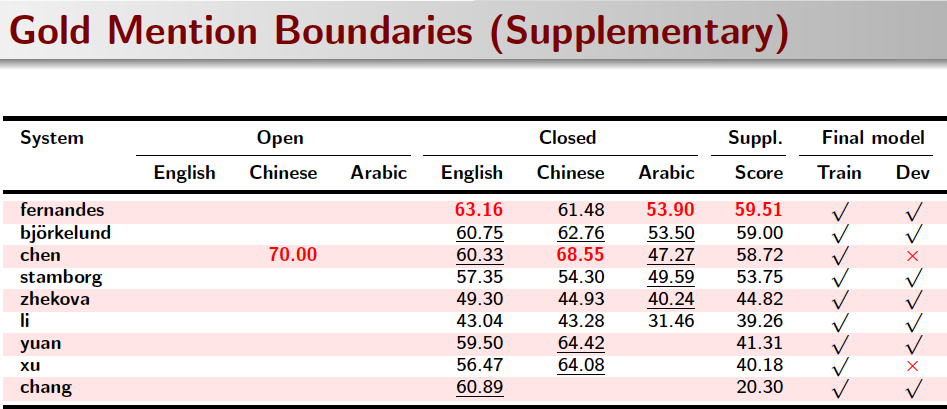
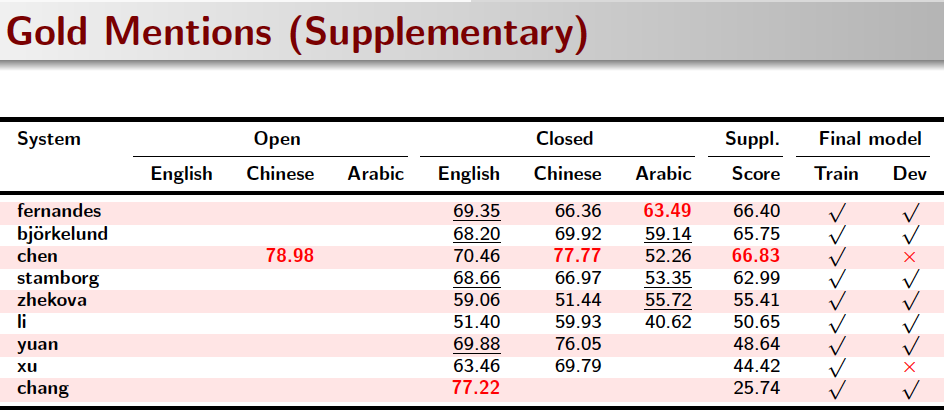
System Results
Program
FAQ